服务器
Tomcat 常见面试题总结
本文内容主要整理自:
- 《深入拆解 Tomcat & Jetty》
- 《Tomcat 架构解析》
感谢这两份资料,尤其是《深入拆解 Tomcat & Jetty》,写的非常赞,看了之后收货颇多。
虽然这篇文章的内容大部分都不是我的原创,但整理重要的知识点和面试题同样花了不少心思,希望对你有帮助!
Tomcat 介绍
什么是 Web 容器?
早期的 Web 应用主要用于浏览新闻等静态页面,HTTP 服务器(比如 Apache、Nginx)向浏览器返回静态 HTML,浏览器负责解析 HTML,将结果呈现给用户。
随着互联网的发展,我们已经不满足于仅仅浏览静态页面,还希望通过一些交互操作,来获取动态结果,因此也就需要一些扩展机制能够让 HTTP 服务器调用服务端程序。
于是 Sun 公司推出了 Servlet 技术。你可以把 Servlet 简单理解为运行在服务端的 Java 小程序,但是 Servlet 没有 main 方法,不能独立运行,因此必须把它部署到 Servlet 容器中,由容器来实例化并调用 Servlet。
Tomcat 就是 一个 Servlet 容器。为了方便使用,Tomcat 同时具有 HTTP 服务器的功能。
因此 Tomcat 就是一个“HTTP 服务器 + Servlet 容器”,我们也叫它 Web 容器。
什么是 Tomcat?
简单来说,Tomcat 就是一个“HTTP 服务器 + Servlet 容器”,我们通常也称呼 Tomcat 为 Web 容器。
HTTP 服务器 :处理 HTTP 请求并响应结果。
Servlet 容器 :HTTP 服务器将请求交给 Servlet 容器处理,Servlet 容器会将请求转发到具体的 Servlet(Servlet 容器用来加载和管理业务类)。
HTTP 服务器工作原理了解吗?
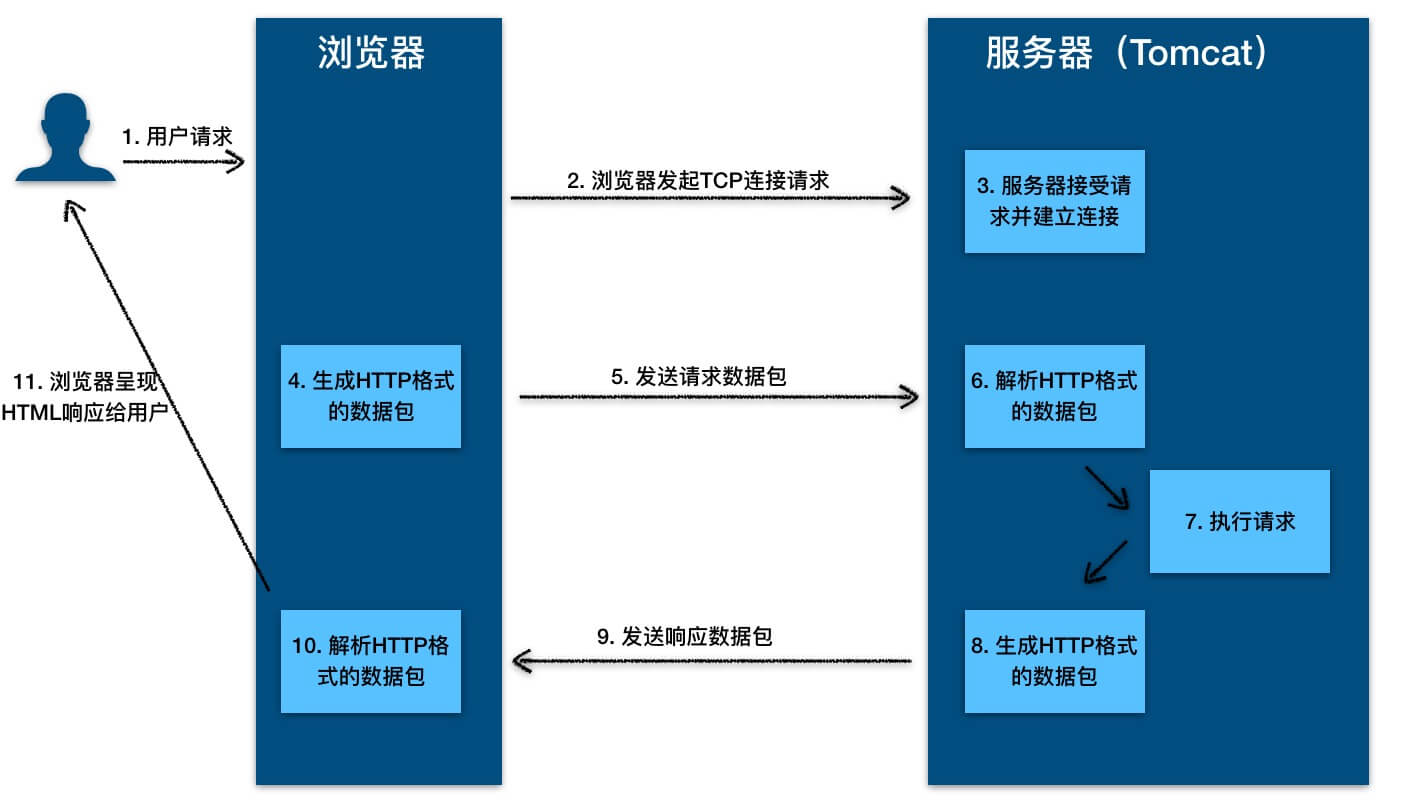
- 用户通过浏览器进行了一个操作,比如输入网址并回车,或者是点击链接,接着浏览器获取了这个事件。
- 浏览器向服务端发出 TCP 连接请求。
- 服务程序接受浏览器的连接请求,并经过 TCP 三次握手建立连接。
- 浏览器将请求数据打包成一个 HTTP 协议格式的数据包。
- 浏览器将该数据包推入网络,数据包经过网络传输,最终达到端服务程序。
- 服务端程序拿到这个数据包后,同样以 HTTP 协议格式解包,获取到客户端的意图。
- 得知客户端意图后进行处理,比如提供静态文件或者调用服务端程序获得动态结果。
- 服务器将响应结果(可能是 HTML 或者图片等)按照 HTTP 协议格式打包。
- 服务器将响应数据包推入网络,数据包经过网络传输最终达到到浏览器。
- 浏览器拿到数据包后,以 HTTP 协议的格式解包,然后解析数据,假设这里的数据是 HTML。
- 浏览器将 HTML 文件展示在页面上。
什么是 Servlet?有什么作用?
Servlet 指的是任何实现了 Servlet 接口的类。Servlet 主要用于处理客户端传来的 HTTP 请求,并返回一个响应。
Servlet 接口定义了下面五个方法:
public interface Servlet {
void init(ServletConfig config) throws ServletException;
ServletConfig getServletConfig();
void service(ServletRequest req, ServletResponse res)throws ServletException, IOException;
String getServletInfo();
void destroy();
}其中最重要是的service方法,具体业务类在这个方法里实现业务的具体处理逻辑。
Servlet 容器会根据 web.xml 文件中的映射关系,调用相应的 Servlet,Servlet 将处理的结果返回给 Servlet 容器,并通过 HTTP 服务器将响应传输给客户端。
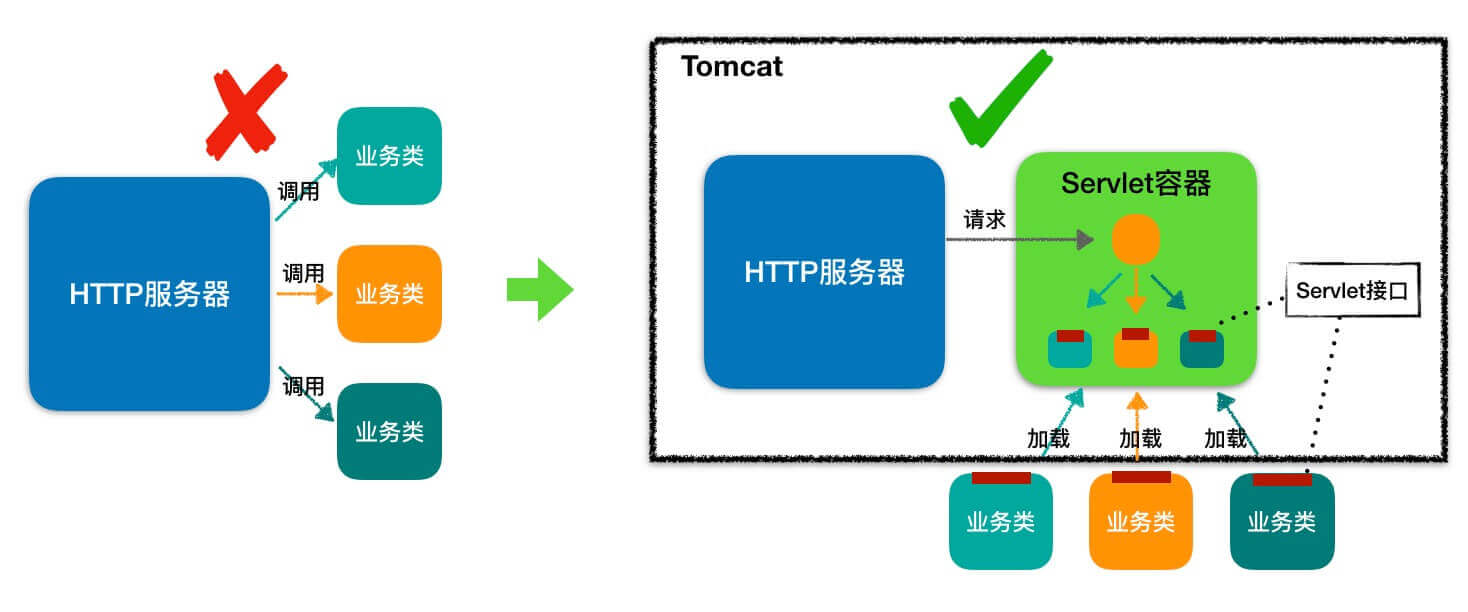
几乎所有的 Java Web 框架(比如 Spring)都是基于 Servlet 的封装。
Tomcat 是如何创建 Servlet 的?
当容器启动时,会读取在 webapps 目录下所有的 web 应用中的 web.xml 文件,然后对 xml 文件进行解析,并读取 servlet 注册信息。然后,将每个应用中注册的 Servlet 类都进行加载,并通过 反射的方式实例化。(有时候也是在第一次请求时实例化)。
<load-on-startup>元素是 <servlet>元素的一个子元素,它用于指定 Servlet 被加载的时机和顺序。在 <load-on-startup>元素中,设置的值必须是一个整数。如果这个值是一个负数,或者没有设定这个元素,Servlet 容器将在客户端首次请求这个 Servlet 时加载它;如果这个值是正整数或 0,Servlet 容器将在 Web 应用启动时加载并初始化 Servlet,并且 <load-on-startup>的值越小,它对应的 Servlet 就越先被加载。
具体配置方式如下所示:
<servlet>
<servlet-name>HelloWorldServlet</servlet-name>
<servlet-class>
cn.itcast.firstapp.servlet.HelloWorldServlet
</servlet-class>
<!--设置Servlet在Web应用启动时初始化-->
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<!--HelloWorldServlet在Tomcat启动时就被自动加载并且初始化了。-->
<servlet-name>HelloWorldServlet</servlet-name>
<url-pattern>/helloWorldServlet</url-pattern>
</servlet-mapping>Tomcat 文件夹
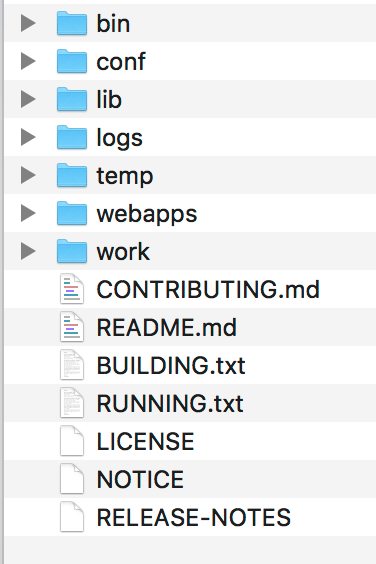
- /bin:存放 Windows 或 Linux 平台上启动和关闭 Tomcat 的脚本文件。
- /conf:存放 Tomcat 的各种全局配置文件,其中最重要的是 server.xml。
- /lib:存放 Tomcat 以及所有 Web 应用都可以访问的 JAR 文件。
- /logs:存放 Tomcat 执行时产生的日志文件。
- /work:存放 JSP 编译后产生的 Class 文件。
- /webapps:Tomcat 的 Web 应用目录,默认情况下把 Web 应用放在这个目录下。
bin 目录有什么作用?
$ ls tomcat/bin
bootstrap.jar configtest.bat setclasspath.bat tcnative-1.dll* tool-wrapper.sh*
catalina.bat configtest.sh* setclasspath.sh* tomcat8.exe* version.bat
catalina.sh* daemon.sh* shutdown.bat tomcat8w.exe* version.sh*
catalina-tasks.xml digest.bat shutdown.sh* tomcat-juli.jar
commons-daemon.jar digest.sh* startup.bat tomcat-native.tar.gz
commons-daemon-native.tar.gz service.bat startup.sh* tool-wrapper.batbin 目录保存了对 Tomcat 进行控制的相关可执行程序。
上面的文件中,主要分为两类:.bat 和 .sh。.bat 是 window 平台的批处理文件,用于在 window 中执行。而 .sh 则是在 Linux 或者 Unix 上执行的。
比较常用的是下面两个:
- startup.sh(startup.bat)用来启动 Tomcat 服务器。
- shutdown.sh(shutdown.bat)用来关闭已经运行的 Tomcat 服务器。
webapps 目录有什么作用?
webapps 目录用来存放应用程序,当 Tomcat 启动时会去加载 webapps 目录下的应用程序。可以以文件夹、war 包、jar 包的形式发布应用。
当然,你也可以把应用程序放置在磁盘的任意位置,在配置文件中映射好就行。
Tomcat 总体架构
Tomcat 要实现 2 个核心功能:
- 处理 Socket 连接,负责网络字节流与 Request 和 Response 对象的转化。
- 加载和管理 Servlet,以及具体处理 Request 请求。
因此 Tomcat 设计了两个核心组件 连接器(Connector) 和 容器(Container) 来分别做这两件事情。
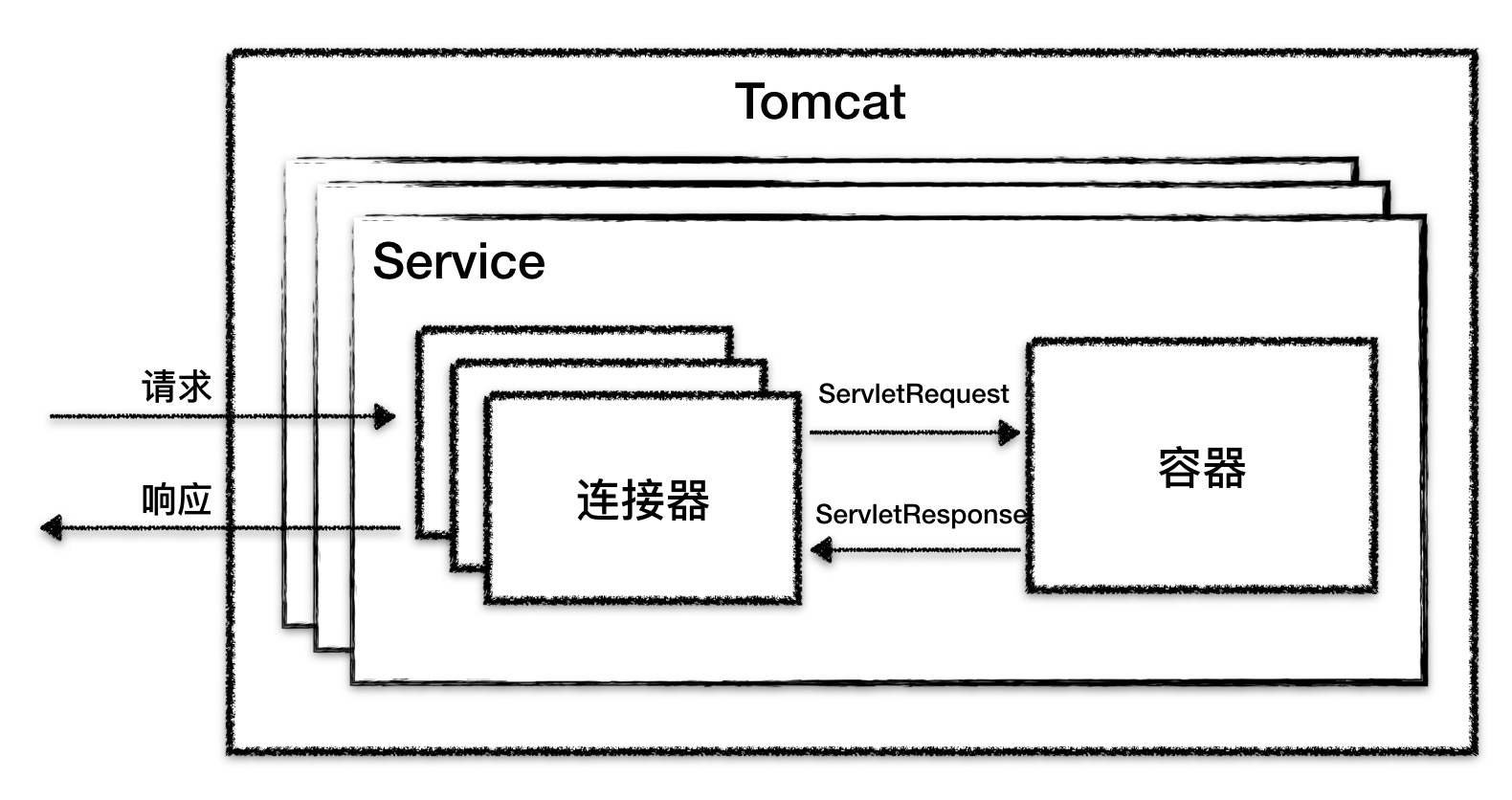
连接器有什么作用?
连接器对 Servlet 容器屏蔽了协议及 I/O 模型等的区别,无论是 HTTP 还是 AJP,在容器中获取到的都是一个标准的ServletRequest对象。
我们可以把连接器的功能需求进一步细化,比如:
- 监听网络端口。
- 接受网络连接请求。
- 读取网络请求字节流。
- 根据具体应用层协议(HTTP/AJP)解析字节流,生成统一的 Tomcat Request 对象。
- 将 Tomcat Request 对象转成标准的 ServletRequest。
- 调用 Servlet 容器,得到 ServletResponse。
- 将 ServletResponse 转成 Tomcat Response 对象。
- 将 Tomcat Response 转成网络字节流。
- 将响应字节流写回给浏览器。
通过分析连接器的详细功能列表,我们发现连接器需要完成 3 个高内聚的功能:
- 网络通信。
- 应用层协议解析。
- Tomcat Request/Response 与 ServletRequest/ServletResponse 的转化。
因此 Tomcat 的设计者设计了 3 个组件来实现这 3 个功能,分别是 Endpoint、Processor 和 Adapter (适配器模式)。
Endpoint 负责提供字节流给 Processor,Processor 负责提供 Tomcat Request 对象给 Adapter,Adapter 负责提供 ServletRequest 对象给容器。
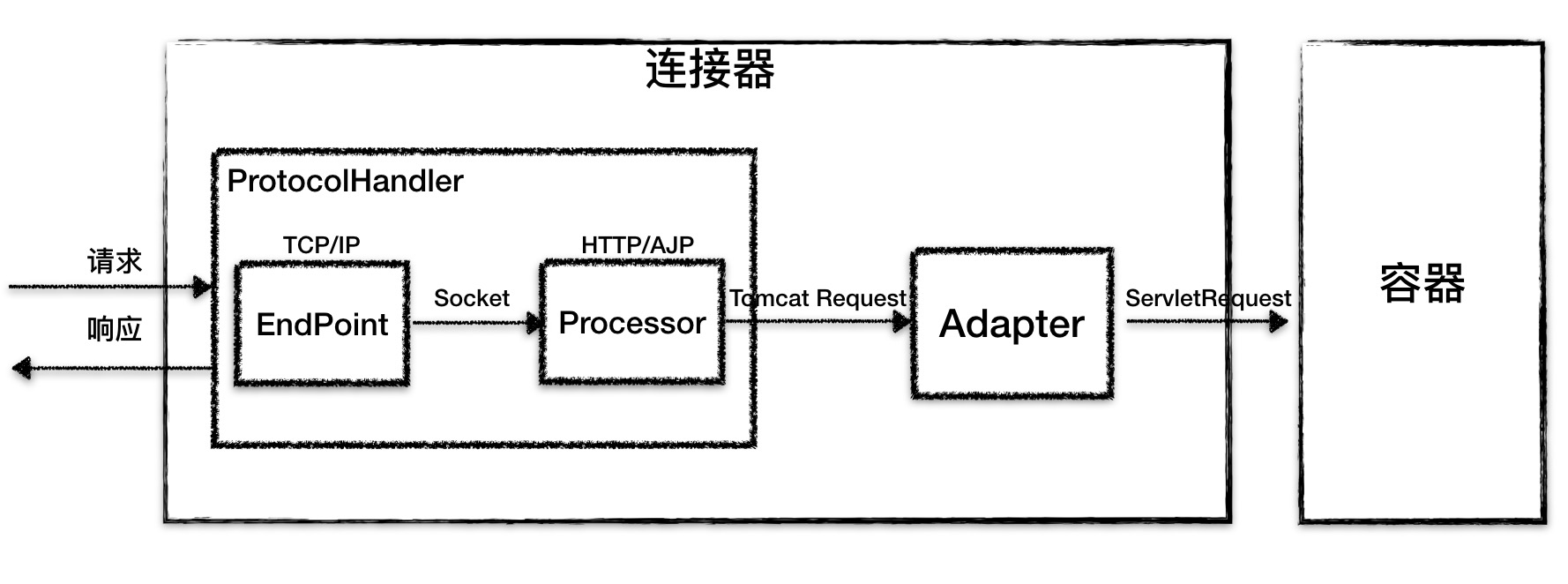
连接器用 ProtocolHandler 接口来封装通信协议和 I/O 模型的差异,ProtocolHandler 内部又分为Endpoint 和 Processor 模块,Endpoint负责底层 Socket 通信,Processor 负责应用层协议解析。连接器通过适配器 Adapter调用容器。
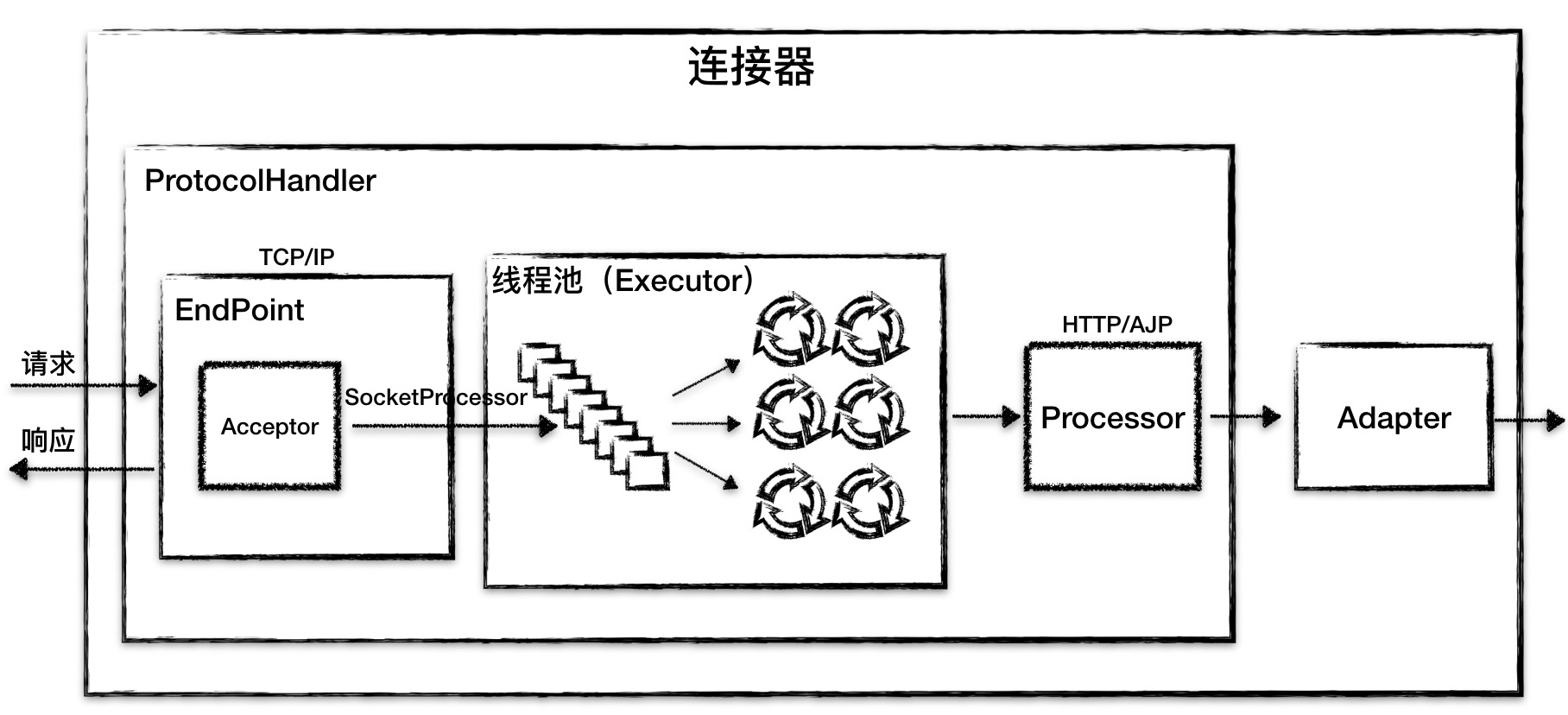
如果要支持新的 I/O 方案、新的应用层协议,只需要实现相关的具体子类,上层通用的处理逻辑是不变的。
容器是怎么设计的?
Tomcat 设计了 4 种容器,分别是 Engine、Host、Context 和 Wrapper。这 4 种容器不是平行关系,而是父子关系。
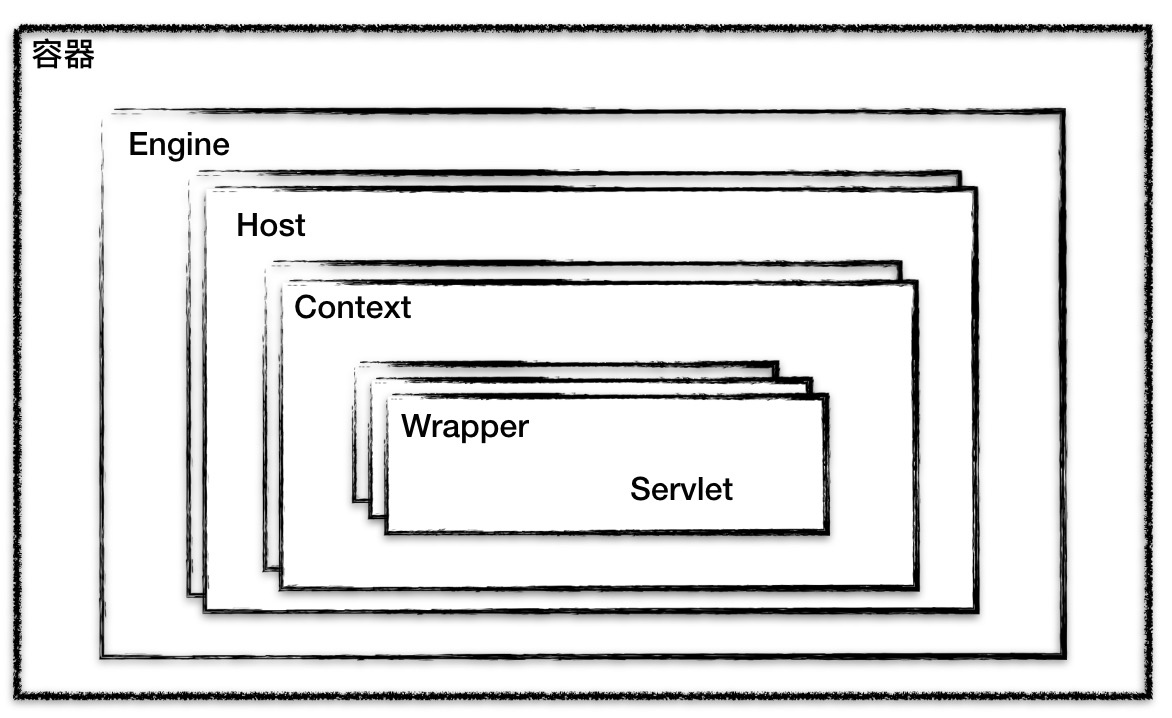
- Context 表示一个 Web 应用程序;
- Wrapper 表示一个 Servlet,一个 Web 应用程序中可能会有多个 Servlet;
- Host 代表的是一个虚拟主机,或者说一个站点,可以给 Tomcat 配置多个虚拟主机地址,而一个虚拟主机下可以部署多个 Web 应用程序;
- Engine 表示引擎,用来管理多个虚拟站点,一个 Service 最多只能有一个 Engine。
你可以再通过 Tomcat 的 server.xml配置文件来加深对 Tomcat 容器的理解。Tomcat 采用了组件化的设计,它的构成组件都是可配置的,其中最外层的是 Server,其他组件按照一定的格式要求配置在这个顶层容器中。

请求是如何定位到 Servlet 的?
Tomcat 是怎么确定请求是由哪个 Wrapper 容器里的 Servlet 来处理的呢?
Mapper`组件的功能就是将用户请求的 URL 定位到一个 Servlet。它的工作原理是:Mapper 组件里保存了 Web 应用的配置信息,其实就是容器组件与访问路径的映射关系,比如 Host 容器里配置的域名、Context 容器里的 Web 应用路径,以及 Wrapper 容器里 Servlet 映射的路径,你可以想象这些配置信息就是一个多层次的 Map。
注意:一个请求 URL 最后只会定位到一个 Wrapper 容器,也就是一个 Servlet。
举个例子:有一个网购系统,有面向网站管理人员的后台管理系统,还有面向终端客户的在线购物系统。这两个系统跑在同一个 Tomcat 上,为了隔离它们的访问域名,配置了两个虚拟域名:manage.shopping.com 和 user.shopping.com 。
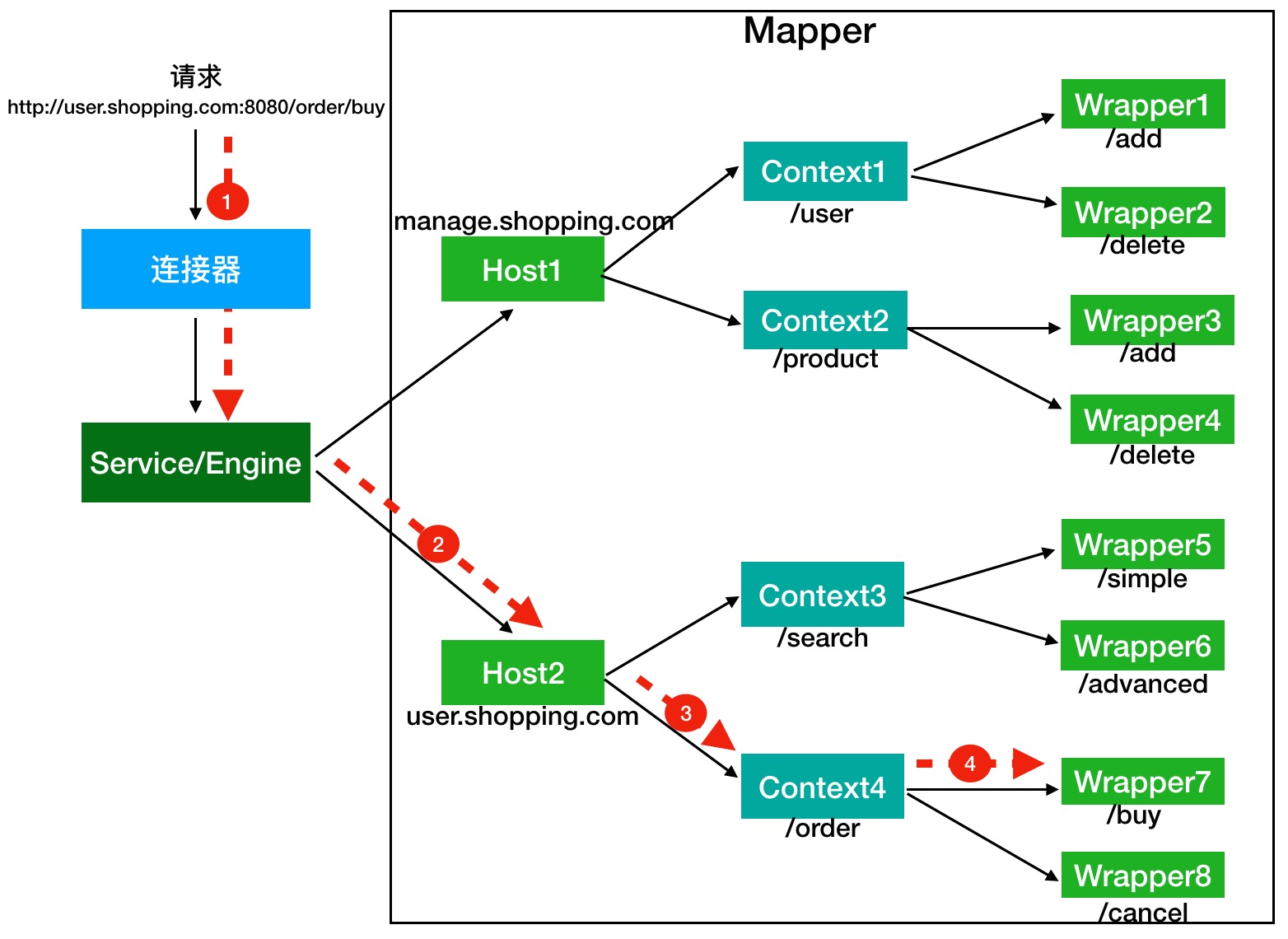
假如有用户访问一个 URL,比如图中的http://user.shopping.com:8080/order/buy,Tomcat 如何将这个 URL 定位到一个 Servlet 呢?
- 根据协议和端口号选定 Service 和 Engine : URL 访问的是 8080 端口,因此这个请求会被 HTTP 连接器接收,而一个连接器是属于一个 Service 组件的,这样 Service 组件就确定了
- 根据域名选定 Host : 域名是 user.shopping.com,因此 Mapper 会找到 Host2 这个容器。
- 根据 URL 路径找到 Context 组件 。
- 根据 URL 路径找到 Wrapper(Servlet) : Context 确定后,Mapper 再根据 web.xml 中配置的 Servlet 映射路径来找到具体的 Wrapper 和 Servlet。
Tomcat 为什么要打破双亲委托机制?
Tomcat 自定义类加载器打破双亲委托机制的目的是为了优先加载 Web 应用目录下的类,然后再加载其他目录下的类,这也是 Servlet 规范的推荐做法。
要打破双亲委托机制,需要继承 ClassLoader 抽象类,并且需要重写它的 loadClass 方法,因为 ClassLoader 的默认实现就是双亲委托。
Tomcat 如何隔离 Web 应用?
首先让我们思考这一下这几个问题:
假如我们在 Tomcat 中运行了两个 Web 应用程序,两个 Web 应用中有同名的 Servlet,但是功能不同,Tomcat 需要同时加载和管理这两个同名的 Servlet 类,保证它们不会冲突,因此 Web 应用之间的类需要隔离。
假如两个 Web 应用都依赖同一个第三方的 JAR 包,比如 Spring,那 Spring 的 JAR 包被加载到内存后,Tomcat 要保证这两个 Web 应用能够共享,也就是说 Spring 的 JAR 包只被加载一次,否则随着依赖的第三方 JAR 包增多,JVM 的内存会膨胀。
跟 JVM 一样,我们需要隔离 Tomcat 本身的类和 Web 应用的类。
为了解决上面这些问题,Tomcat 设计了类加载器的层次结构。
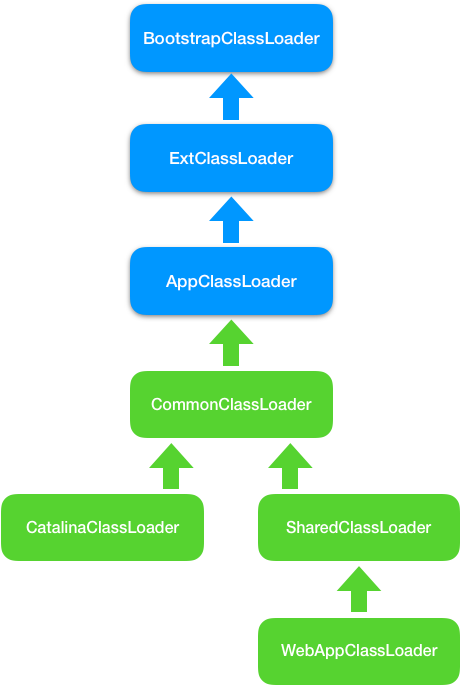
我们先来看第 1 个问题: Web 应用之间的类之间如何隔离?
假如我们使用 JVM 默认AppClassLoader 来加载 Web 应用,AppClassLoader 只能加载一个Servlet 类,在加载第二个同名Servlet类时,AppClassLoader 会返回第一个Servlet 类的 Class实例,这是因为在 AppClassLoader 看来,同名的 Servlet类只被加载一次。
Tomcat 的解决方案是自定义一个类加载器 WebAppClassLoader, 并且给每个 Web 应用创建一个类加载器实例。 我们知道,Context 容器组件对应一个 Web 应用,因此,每个 Context 容器负责创建和维护一个 WebAppClassLoader 加载器实例。这背后的原理是,不同的加载器实例加载的类被认为是不同的类,即使它们的类名相同。这就相当于在 Java 虚拟机内部创建了一个个相互隔离的 Java 类空间,每一个 Web 应用都有自己的类空间,Web 应用之间通过各自的类加载器互相隔离。
我们再来看第 2 个问题: 两个 Web 应用之间怎么共享库类,并且不能重复加载相同的类?
我们知道,在双亲委托机制里,各个子加载器都可以通过父加载器去加载类,那么把需要共享的类放到父加载器的加载路径下不就行了吗,应用程序也正是通过这种方式共享 JRE 的核心类。因此 Tomcat 的设计者又加了一个类加载器 SharedClassLoader,作为 WebAppClassLoader 的父加载器,专门来加载 Web 应用之间共享的类。如果 WebAppClassLoader 自己没有加载到某个类,就会委托父加载器 SharedClassLoader 去加载这个类,SharedClassLoader 会在指定目录下加载共享类,之后返回给 WebAppClassLoader,这样共享的问题就解决了。
我们再来看第 3 个问题:如何隔离 Tomcat 本身的类和 Web 应用的类?
我们知道,要共享可以通过父子关系,要隔离那就需要兄弟关系了。兄弟关系就是指两个类加载器是平行的,它们可能拥有同一个父加载器,但是两个兄弟类加载器加载的类是隔离的。基于此 Tomcat 又设计一个类加载器 CatalinaClassLoader,专门来加载 Tomcat 自身的类。这样设计有个问题,那 Tomcat 和各 Web 应用之间需要共享一些类时该怎么办呢?
老办法,还是再增加一个 CommonClassLoader,作为CatalinaClassLoader和 SharedClassLoader 的父加载器。CommonClassLoader 能加载的类都可以被 CatalinaClassLoader 和 SharedClassLoader 使用,而 CatalinaClassLoader 和 SharedClassLoader 能加载的类则与对方相互隔离。WebAppClassLoader 可以使用 SharedClassLoader加载到的类,但各个 WebAppClassLoader实例之间相互隔离。
性能优化
如何监控 Tomcat 性能?
Tomcat 的关键的性能指标主要有 吞吐量、响应时间、错误数、线程池、CPU 以及 JVM 内存。
通过 JConsole 监控 Tomcat
命令行查看 Tomcat 指标
prometheus + grafana
JVM GC 原理及调优的基本思路
Tomcat 基于 Java,也是跑在 JVM 中,因此,我们要对 Tomcat 进行调优的话,先要了解 JVM 调优的原理。
**JVM 调优主要是对 JVM 垃圾收集的优化。**一般来说是因为有问题才需要优化,所以对于 JVM GC 来说,如果你观察到 Tomcat 进程的 CPU 使用率比较高,并且在 GC 日志中发现 GC 次数比较频繁、GC 停顿时间长,这表明你需要对 GC 进行优化了。
在对 GC 调优的过程中,我们不仅需要知道 GC 的原理,更重要的是要熟练使用各种监控和分析工具,具备 GC 调优的实战能力。
**CMS 和 G1 是时下使用率比较高的两款垃圾收集器,从 Java 9 开始,采用 G1 作为默认垃圾收集器,**而 G1 的目标也是逐步取代 CMS。
如何选择 IO 模型?
I/O 调优实际上是连接器类型的选择,一般情况下默认都是 NIO,在绝大多数情况下都是够用的,除非你的 Web 应用用到了 TLS 加密传输,而且对性能要求极高,这个时候可以考虑 APR,因为 APR 通过 OpenSSL 来处理 TLS 握手和加 / 解密。OpenSSL 本身用 C 语言实现,它还对 TLS 通信做了优化,所以性能比 Java 要高。
那你可能会问那什么时候考虑选择 NIO.2?
如果你的 Tomcat 跑在 Windows 平台上,并且 HTTP 请求的数据量比较大,可以考虑 NIO.2,这是因为 Windows 从操作系统层面实现了真正意义上的异步 I/O,如果传输的数据量比较大,异步 I/O 的效果就能显现出来。
如果你的 Tomcat 跑在 Linux 平台上,建议使用 NIO,这是因为 Linux 内核没有很完善地支持异步 I/O 模型,因此 JVM 并没有采用原生的 Linux 异步 I/O,而是在应用层面通过 epoll 模拟了异步 I/O 模型,只是 Java NIO 的使用者感觉不到而已。因此可以这样理解,在 Linux 平台上,Java NIO 和 Java NIO.2 底层都是通过 epoll 来实现的,但是 Java NIO 更加简单高效。
Nginx 常见面试题总结
什么是 Nginx ?
俄罗斯的工程师 Igor Sysoev,在 Rambler Media 工作期间使用 C 语言开发并开源了 Nginx。
Nginx 同 Apache 一样都是 WEB 服务器,不过,Nginx 更加轻量级,它的内存占用少,启动极快,高并发能力强,在互联网项目中广泛应用。并且,Nginx 可以作为反向代理服务器使用,支持 IMAP/POP3/SMTP 服务。
Web 服务器:负责处理和响应用户请求,一般也称为 HTTP 服务器。
Nginx 的特点是有哪些?
内存占用非常少 :一般情况下,10000 个非活跃的 HTTP Keep-Alive 连接在 Nginx 中仅消耗 2.5MB 的内存,这是 Nginx 支持高并发连接的基础。
高并发 : 单机支持 10 万以上的并发连接
跨平台 :可以运行在 Linux,Windows,FreeBSD,Solaris,AIX,Mac OS 等操作系统上。
扩展性好 :第三方插件非常多!
安装使用简单 :对于简单的应用场景,我们很快就能够上手使用。
稳定性好 :bug 少,不会遇到各种奇葩的问题。
免费 :开源软件,免费使用。
......
Nginx 能用来做什么?
静态资源服务器
Nginx 是一个 HTTP 服务器,可以将服务器上的静态文件(如 HTML、图片)通过 HTTP 协议展现给客户端。因此,我们可以使用 Nginx 搭建静态资源 Web 服务器
不过,记得使用 gzip 压缩静态资源来减少网络传输。
举个例子:我们来使用 Nginx 搭建一个静态网页服务。先将静态网页上传到服务器,然后修改/nginx/conf目录下的 nginx.conf文件(Nginx 配置文件)。修改完成之后,重启 Nginx,再请求对应 ip/域名 + 端口 + 资源地址就可以访问到网页。
server {
// 监听的端口号
listen 80;
// server 名称
server_name localhost;
// 匹配 api,将所有 :80/api 的请求指到指定文件夹
location /api {
root /mnt/web/;
// 默认打开 index.html
index index.html index.htm;
}
}反向代理
客户端将请求发送到反向代理服务器,由反向代理服务器去选择目标服务器,获取数据后再返回给客户端。对外暴露的是反向代理服务器地址,隐藏了真实服务器 IP 地址。反向代理“代理”的是目标服务器,这一个过程对于客户端而言是透明的。
举个例子:公司内网部署了 3 台服务器,客户端请求直接经过代理服务器,由代理服务器将请求转发到内网服务器并最终决定哪一台服务器处理客户端请求。
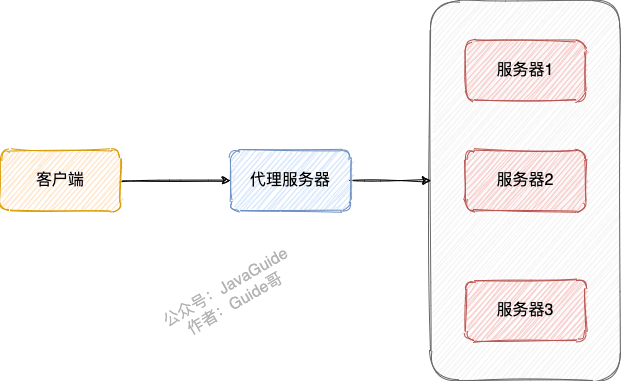
反向代理隐藏了真实的服务器,为服务器收发请求,使真实服务器对客户端不可见。一般在处理跨域请求的时候比较常用。现在基本上所有的大型网站都设置了反向代理。
Nginx 支持配置反向代理,通过反向代理实现网站的负载均衡。
正向代理
提示 :想要理解正确理解和区分正向代理和反向代理,你要关注的是代理对象,正向代理“代理”的是客户端,反向代理“代理”的是目标服务器。
一位大佬说的一句话挺精辟的:代理其实就是一个中介,A 和 B 本来可以直连,中间插入一个 C,C 就是中介。刚开始的时候,代理多数是帮助内网 client 访问外网 server 用的(比如 HTTP 代理),从内到外 . 后来出现了反向代理,"反向"这个词在这儿的意思其实是指方向相反,即代理将来自外网 client 的请求 forward 到内网 server,从外到内
Nginx 主要被作为反向代理服务器使用,不过,其同样也是正向代理服务器的一个选择。
客户端通过正向代理服务器访问目标服务器。正向代理“代理”的是客户端,目标服务器不知道客户端是谁,也就是说客户端对目标服务器的这次访问是透明的。
为了实现正向代理,客户端需要设置正向代理服务器的 IP 地址以及代理程序的端口。
举个例子:我们无法直接访问外网,但是可以借助科学上网工具 VPN 来访问。VPN 会把访问外网服务器(目标服务器)的客户端请求代理到一个可以直接访问外网的代理服务器上去。代理服务器会把外网服务器返回的内容再转发给客户端。
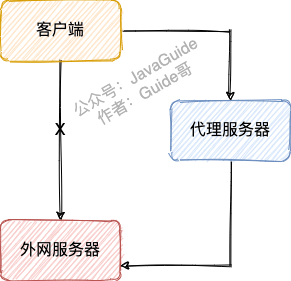
外网服务器并不知道客户端是通过 VPN 访问的
简单来说: 你可以将正向代理看作是一个位于客户端和目标服务器之间的代理服务器,其主要作用就是转达客户端请求从目标服务器上获取指定的内容。
相关阅读:
负载均衡
如果一台服务器处理用户请求处理不过来的话,一个简单的办法就是增加多台服务器(服务器集群)部署相同的服务来处理用户请求。
Nginx 可以将接收到的客户端请求以一定的规则(负载均衡策略)均匀地分配到这个服务器集群中所有的服务器上,这个就叫做 负载均衡。
可以看出,Nginx 在其中充当的就是反向代理服务器的作用,负载均衡正是 Nginx 作为反向代理服务器最常见的一个应用。
除此之外,Nginx 还带有健康检查(服务器心跳检查)功能,会定期轮询向集群里的所有服务器发送健康检查请求,来检查集群中是否有服务器处于异常状态。

动静分离
动静分离就是把动态请求和静态请求分开,不是讲动态页面和静态页面物理分离,可以理解为 Nginx 处理静态页面,Tomcat 或者其他 Web 服务器处理动态页面。
动静分离可以减轻 Tomcat 或者其他 Web 服务器的压力,提高网站响应速度。
Nginx 有哪些负载均衡策略?
相关参考:
Nginx 的负载均衡策略不止下面介绍的这四种,我这里只是列举几个比较常用的负载均衡策略。
轮询(Round Robin,默认)
轮询为负载均衡中较为基础也较为简单的算法。
如果没有配置权重的话,每个请求按时间顺序逐一分配到不同的服务器处理。
upstream backserver {
server 172.27.26.174:8099;
server 172.27.26.175:8099;
server 172.27.26.176:8099;
}如果配置权重的话,权重越高的服务器被访问的概率就越大。
upstream backserver {
server 172.27.26.174:8099 weight=6;
server 172.27.26.175:8099 weight=2;
server 172.27.26.176:8099 weight=3;
}未加权重的轮询算法适合于服务器性能相近的集群,其中每个服务器承载相同的负载。加权轮询算法适合于服务器性能不等的集群,权重的存在可以使请求分配更加合理化。
IP 哈希
根据发出请求的和护短 ip 的 hash 值来分配服务器,可以保证同 IP 发出的请求映射到同一服务器,或者具有相同 hash 值的不同 IP 映射到同一服务器。
upstream backserver {
ip_hash;
server 172.27.26.174:8099;
server 172.27.26.175:8099;
server 172.27.26.176:8099;
}和轮询一样,IP 哈希也可以配置权重,如果有两个活动连接数相同的服务器,权重大的被访问的概率就越大。
该算法在一定程度上解决了集群部署环境下 Session 不共享的问题。
最小连接数
当有新的请求出现时,遍历服务器节点列表并选取其中活动连接数最小的一台服务器来响应当前请求。活动连接数可以理解为当前正在处理的请求数。
upstream backserver {
least_conn;
server 172.27.26.174:8099;
server 172.27.26.175:8099;
server 172.27.26.176:8099;
}Nginx 常用命令有哪些?
- 启动 nginx 。
- 停止 nginx -s stop 或 nginx -s quit 。
- 重载配置 ./sbin/nginx -s reload(平滑重启) 或 service nginx reload 。
- 重载指定配置文件 .nginx -c /usr/local/nginx/conf/nginx.conf 。
- 查看 nginx 版本 nginx -v 。
- 检查配置文件是否正确 nginx -t 。
- 显示帮助信息 nginx -h 。
Nginx 性能优化的常见方式?
设置 Nginx 运行工作进程个数 :一般设置 CPU 的核心数或者核心数 x2;
开启 Gzip 压缩 :这样可以使网站的图片、CSS、JS 等文件在传输时进行压缩,提高访问速度, 优化 Nginx 性能。详细介绍可以参考Nginx 性能优化功能- Gzip 压缩(大幅度提高页面加载速度)这篇文章;
设置单个 worker 进程允许客户端最大连接数 :一般设置为 65535 就足够了;
连接超时时间设置 :避免在建立无用连接上消耗太多资源;
设置缓存 :像图片、CSS、JS 等这类一般不会经常修改的文件,我们完全可以设置图片在浏览器本地缓存,提高访问速度,优化 Nginx 性能。
......
LVS、Nginx、HAproxy 有什么区别?
LVS、Nginx、HAProxy 是目前使用最广泛的三种软件负载均衡软件。
LVS 是 Linux Virtual Server 的简称,也就是 Linux 虚拟服务器。LVS 是四层负载均衡,建立在 OSI 模型的第四层(传输层)之上,性能非常强大。
HAProxy 可以工作在四层和七层(传输层和应用层),是专门用来做代理服务器的。
Nginx 负载均衡主要是对七层网络通信模型中的第七层应用层上的 HTTP、HTTPS 进行支持。Nginx 是以反向代理的方式进行负载均衡的。
Nginx 如何实现后端服务健康检查?
我们可以利用第三方模块 upstream_check_module 来检测后端服务的健康状态,如果后端服务器不可用,则所有的请求不转发到这台服务器。
upstream_check_module 是一款阿里的一位大佬开源的,使用 Perl 和 C 编写而成,Github 地址 :https://github.com/yaoweibin/nginx_upstream_check_module 。
关于 upstream_check_module 实现后端服务健康检查的具体做法可以参考Nginx 负载均衡健康检查功能这篇文章。
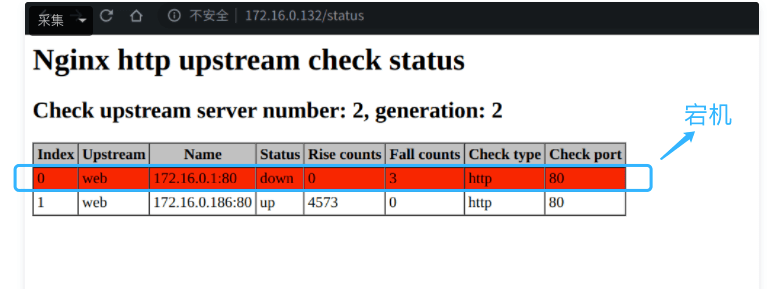
如何保证 Nginx 服务的高可用?
Nginx 可以结合 Keepalived 来实现高可用。
什么是 Keepalived ? 根据官网介绍:
Keepalived 是一个用 C 语言编写的开源路由软件,是 Linux 下一个轻量级别的负载均衡和高可用解决方案。Keepalived 的负载均衡依赖于众所周知且广泛使用的 Linux 虚拟服务器 (IPVS 即 IP Virtual Server,内置在 Linux 内核中的传输层负载均衡器) 内核模块,提供第 4 层负载平衡。Keepalived 实现了一组检查器用于根据服务器节点的健康状况动态维护和管理服务器集群。
Keepalived 的高可用性是通过虚拟路由冗余协议(VRRP 即 Virtual Router Redundancy Protocol,实现路由器高可用的协议)实现的,可以用来解决单点故障。
Github 地址:https://github.com/acassen/keepalived
Keepalived 不仅仅可以和 Nginx 搭配使用,还可以和 LVS、MySQL、HAProxy 等软件配合使用。
再来简单介绍一下 Keepalived+Nginx 实现高可用的常见方法:
- 准备 2 台 Nginx 服务器,一台为主服务,一台为备用服务;
- 在两台 Nginx 服务器上安装并配置 Keepalived;
- 为两台 Nginx 服务器绑定同一个虚拟 IP;
- 编写 Nginx 检测脚本用于通过 Keepalived 检测 Nginx 主服务器的状态是否正常;
如果 Nginx 主服务器宕机的话,会自动进行故障转移,备用 Nginx 主服务器升级为主服务。并且,这个切换对外是透明的,因为使用的虚拟 IP,虚拟 IP 不会改变。
相关阅读:
📄友情提示 :下面的内容属于 Nginx 的进阶指点,主要是一些 Nginx 底层原理相关的知识。你可以根据自身情况选择是否掌握这部分内容,如果你的简历没有写熟练掌握 Nginx 使用及原理的话,面试官一般不会问这么深入。
Nginx 总体架构了解吗?
关于 Nginx 总结架构的详细解答,请看这篇文章:最近和 Nginx 杠上了!
对于传统的 HTTP 和反向代理服务器而言,在处理并发请求的时候会使用单进程或线程的模式处理,同时会止网络或输入/输出操作。
这种方式会消耗大量的内存和 CPU 资源。因为每产生一个单独的进程或线程需要准备一套新的运行时环境,包括分配堆和堆栈内存,以及创建新的执行上下文。
可以想象在处理多请求时会生成对应数目的线程或进程,导致由于线程在不断上下文切换上耗费大量资源。
由于上面的原因,Nginx 在设计之初就使用了模块化、事件驱动、异步处理,非阻塞的架构。
一张图来了解 Nginx 的总结架构:
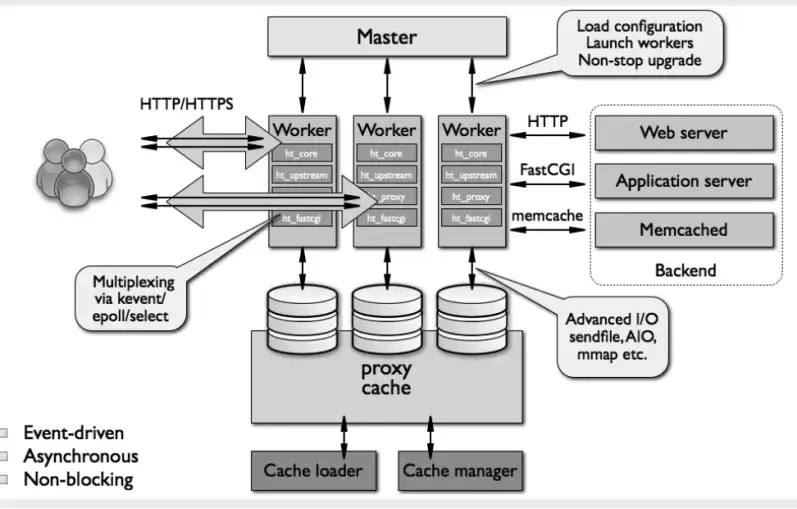
Nginx 进程模型了解么?
关于进程模型的详细解答,请看这篇文章:Nginx 工作模式和进程模型
Nginx 启动后,会产生一个 master 主进程,主进程执行一系列的工作后会产生一个或者多个工作进程 worker 进程。master 进程用来管理 worker 进程, worker 进程负责处理网络请求。也就是说 Nginx 采用的是经典的 master-worker 模型的多进程模型 。
Nginx 如何处理 HTTP 请求?
系统学习
Guide 整理了下面一些文章和书籍帮助你系统学习 Nginx。
文章推荐
书籍推荐
《深入理解 Nginx(第 2 版)》 这本书是初学者学习 Nginx 的首选,讲的非常细致!
Devops
监控系统常见面试题总结
个人学习笔记,大部分内容整理自书籍、博客和官方文档。
相关文章 &书籍:
相关视频:
- 使用Prometheus实践基于Spring Boot监控告警体系
- [Prometheus & Grafana -陈嘉鹏 尚硅谷大数据]
监控系统有什么用?
建立完善的监控体系主要是为了:
**长期趋势分析 :**通过对监控样本数据的持续收集和统计,对监控指标进行长期趋势分析。例如,通过对磁盘空间增长率的判断,我们可以提前预测在未来什么时间节点上需要对资源进行扩容。
**数据可视化 :**通过可视化仪表盘能够直接获取系统的运行状态、资源使用情况、以及服务运行状态等直观的信息。
预知故障和告警 : 当系统出现或者即将出现故障时,监控系统需要迅速反应并通知管理员,从而能够对问题进行快速的处理或者提前预防问题的发生,避免出现对业务的影响。
辅助定位故障、性能调优、容量规划以及自动化运维
出任何线上事故,先不说其他地方有问题,监控部分一定是有问题的。
如何才能更好地使用监控使用?
**了解监控对象的工作原理:**要做到对监控对象有基本的了解,清楚它的工作原理。比如想对 JVM 进行监控,你必须清楚 JVM 的堆内存结构和垃圾回收机制。
**确定监控对象的指标:**清楚使用哪些指标来刻画监控对象的状态?比如想对某个接口进行监控,可以采用请求量、耗时、超时量、异常量等指标来衡量。
**定义合理的报警阈值和等级:**达到什么阈值需要告警?对应的故障等级是多少?不需要处理的告警不是好告警,可见定义合理的阈值有多重要,否则只会降低运维效率或者让监控系统失去它的作用。
**建立完善的故障处理流程:**收到故障告警后,一定要有相应的处理流程和 oncall 机制,让故障及时被跟进处理。
常见的监控对象和指标有哪些?
**硬件监控 :**电源状态、CPU 状态、机器温度、风扇状态、物理磁盘、raid 状态、内存状态、网卡状态
**服务器基础监控 :**CPU、内存、磁盘、网络
**数据库监控 :**数据库连接数、QPS、TPS、并行处理的会话数、缓存命中率、主从延时、锁状态、慢查询
中间件监控 :
Nginx:活跃连接数、等待连接数、丢弃连接数、请求量、耗时、5XX 错误率
Tomcat:最大线程数、当前线程数、请求量、耗时、错误量、堆内存使用情况、GC 次数和耗时
缓存 :成功连接数、阻塞连接数、已使用内存、内存碎片率、请求量、耗时、缓存命中率
消息队列:连接数、队列数、生产速率、消费速率、消息堆积量
应用监控 :
HTTP 接口:URL 存活、请求量、耗时、异常量
RPC 接口:请求量、耗时、超时量、拒绝量
JVM :GC 次数、GC 耗时、各个内存区域的大小、当前线程数、死锁线程数
线程池:活跃线程数、任务队列大小、任务执行耗时、拒绝任务数
连接池:总连接数、活跃连接数
日志监控:访问日志、错误日志
业务指标:视业务来定,比如 PV、订单量等
监控的基本流程了解吗?
无论是开源的监控系统还是自研的监控系统,监控的整个流程大同小异,一般都包括以下模块:
**数据采集:**采集的方式有很多种,包括日志埋点进行采集(通过 Logstash、Filebeat 等进行上报和解析),JMX 标准接口输出监控指标,被监控对象提供 REST API 进行数据采集(如 Hadoop、ES),系统命令行,统一的 SDK 进行侵入式的埋点和上报等。
**数据传输:**将采集的数据以 TCP、UDP 或者 HTTP 协议的形式上报给监控系统,有主动 Push 模式,也有被动 Pull 模式。
**数据存储:**有使用 MySQL、Oracle 等 RDBMS 存储的,也有使用时序数据库 RRDTool、OpentTSDB、InfluxDB 存储的,还有使用 HBase 存储的。
**数据展示:**数据指标的图形化展示。
**监控告警:**灵活的告警设置,以及支持邮件、短信、IM 等多种通知通道。
监控系统需要满足什么要求?
**实时监控&告警 :**监控系统对业务服务系统实时监控,如果产生系统异常及时告警给相关人员。
**高可用 :**要保障监控系统的可用性
**故障容忍 :**监控系统不影响业务系统的正常运行,监控系统挂了,应用正常运行。
**可扩展 :**支持分布式、跨 IDC 部署,横向扩展。
**可视化 :**自带可视化图标、支持对接各类可视化组件比如 Grafana 。
监控系统技术选型有哪些?如何选择?
老牌监控系统
Zabbix 和 Nagios 相继出现在 1998 年和 1999 年,目前已经被淘汰,不太建议使用,Prometheus 是更好的选择。
Zabbix
**介绍 :**老牌监控的优秀代表。产品成熟,监控功能很全面,采集方式丰富(支持 Agent、SNMP、JMX、SSH 等多种采集方式,以及主动和被动的数据传输方式),使用也很广泛,差不多有 70%左右的互联网公司都曾使用过 Zabbix 作为监控解决方案。
开发语言 : C
数据存储 : Zabbix 存储在 MySQL 上,也可以存储在其他数据库服务。Zabbix 由于使用了关系型数据存储时序数据,所以在监控大规模集群时常常在数据存储方面捉襟见肘。所以从 Zabbix 4.2 版本后开始支持 TimescaleDB 时序数据库,不过目前成熟度还不高。
数据采集方式 : Zabbix 通过 SNMP、Agent、ICMP、SSH、IPMI 等对系统进行数据采集。Zabbix 采用的是 Push 模型(客户端发送数据给服务端)。
**数据展示 :**自带展示界面,也可以对接 Grafana。
**评价 :**不太建议使用 Zabbix,性能可能会成为监控系统的瓶颈。并且,应用层监控支持有限、二次开发难度大(基于 c 语言)、数据模型不强大。
相关阅读:《zabbix 运维手册》
Nagios
**介绍 :**Nagios 能有效监控 Windows、Linux 和 UNIX 的主机状态(CPU、内存、磁盘等),以及交换机、路由器等网络设备(SMTP、POP3、HTTP 和 NNTP 等),还有 Server、Application、Logging,用户可自定义监控脚本实现对上述对象的监控。Nagios 同时提供了一个可选的基于浏览器的 Web 界面,以方便系统管理人员查看网络状态、各种系统问题以及日志等。
开发语言 : C
数据存储 : MySQL 数据库
数据采集方式 : 通过各种插件采集数据
**数据展示 :**自带展示界面,不过功能简单。
**评价 :**不符合当前监控系统的要求,而且,Nagios 免费版本的功能非常有限,运维管理难度非常大。
新一代监控系统
相比于老牌监控系统,新一代监控系统有明显的优势,比如:灵活的数据模型、更成熟的时序数据库、强大的告警功能。

Open-Falcon
- **介绍 :**小米 2015 年开源的企业级监控工具,在架构设计上吸取了 Zabbix 的经验,同时很好地解决了 Zabbix 的诸多痛点。Github 地址:https://github.com/open-falcon 。官方文档:https://book.open-falcon.org/ 。
- **开发语言 :**Go、Python。
- 数据存储 : 环型数据库,支持对接时序数据库 OpenTSDB。
- 数据采集方式 : 自动发现,支持 falcon-agent、snmp、支持用户主动 push、用户自定义插件支持、opentsdb data model like(timestamp、endpoint、metric、key-value tags)。Open-Falcon 和 Zabbix 采用的都是 Push 模型(客户端发送数据给服务端)。
- **数据展示 :**自带展示界面,也可以对接 Grafana。
- **评价 :**用户集中在国内,流行度一般,生态一般。
Open-Falcon 架构图如下:
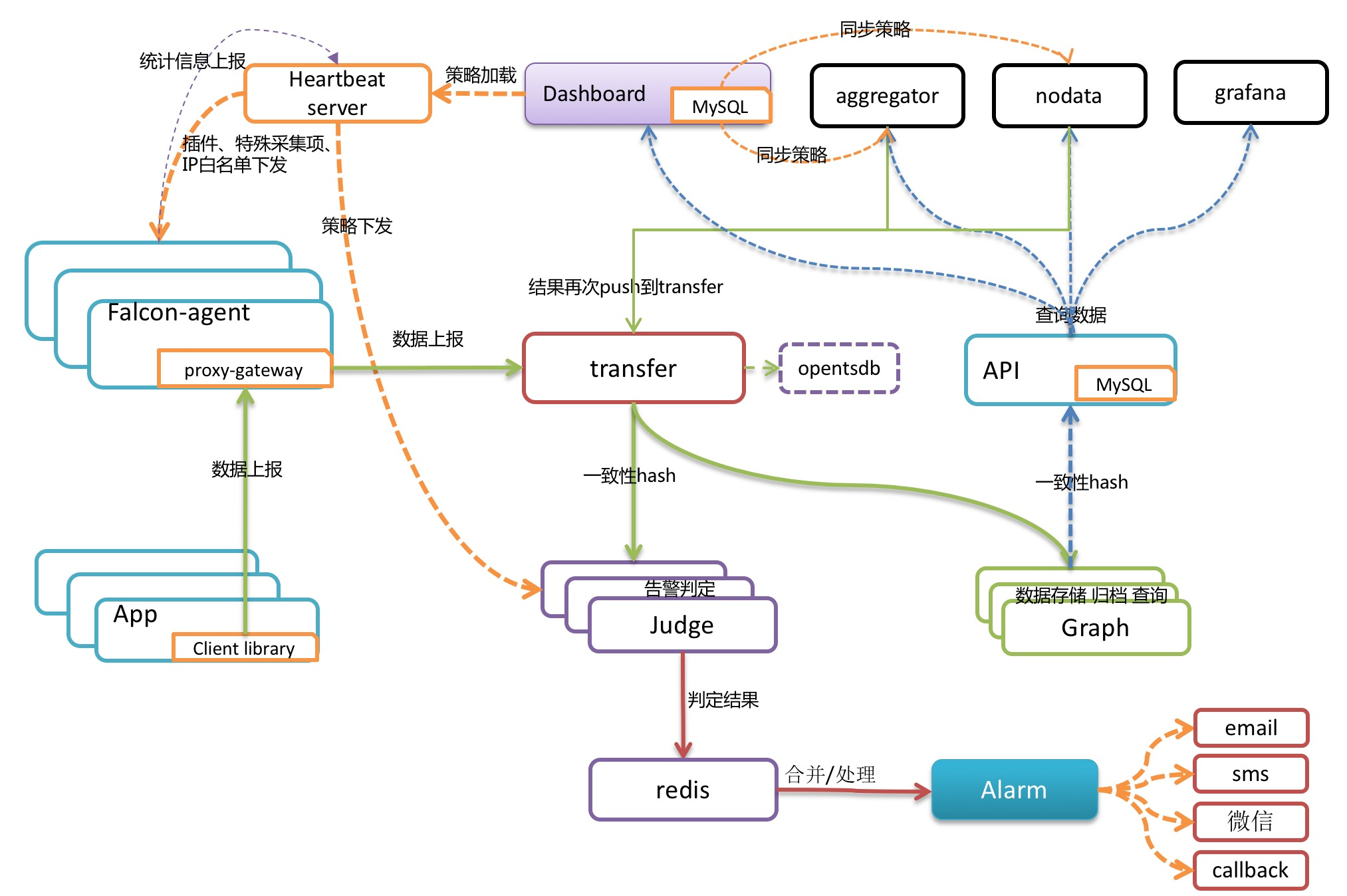
- **Falcon-agent :**采集模块。类似 Zabbix 的 agent,Kubernetes 自带监控体系中的 cAdvisor,Nagios 中的 Plugin,使用 Go 语言开发,用于采集主机上的各种指标数据。
- **Hearthbeat server :**心跳服务。每个 Agent 都会周期性地通过 RPC 方式将自己地状态上报给 HBS,主要包括主机名、主机 IP、Agent 版本和插件版本,Agent 还会从 HBS 获取自己需要执行的采集任务和自定义插件。
- **Transfer :**负责监控 agent 发送的监控数据,并对数据进行处理,在过滤后通过一致性 Hash 算法将数据发送到 Judge 或者 Graph。为了支持存储大量的历史数据,Transfer 还支持 OpenTSDB。Transfer 本身没有状态,可以随意扩展。
- **Jedge :**告警模块。Transfer 转发到 Judge 的数据会触发用户设定的告警规则,如果满足,则会触发邮件、微信或者回调接口。这里为了避免重复告警,引入了 Redis 暂存告警,从而完成告警合并和抑制。
- **Graph :**RRD 数据上报、归档、存储的组件。Graph 在收到数据以后,会以 RRDtool 的数据归档方式存储数据,同时提供 RPC 方式的监控查询接口。
- API : 查询模块。主要提供查询接口,不但可以从 Grapg 里面读取数据,还可以对接 MySQL,用于保存告警、用户等信息。
- Dashboard : 监控数据展示面板。由 Python 开发而成,提供 Open-Falcon 的数据和告警展示,监控数据来自 Graph,Dashboard 允许用户自定义监控面板。
- Aggregator : 聚合模块。聚合某集群下所有机器的某个指标的值,提供一种集群视角的监控体验。 通过定时从 Graph 获取数据,按照集群聚合产生新的监控数据并将监控数据发送到 Transfer。
Prometheus
- **介绍 :**Prometheus 受启发于 Google 的 Brogmon 监控系统,由前 Google 员工 2015 年正式发布。截止到 2021 年 9 月 2 日,Prometheus 在 Github 上已经收获了 38.5k+ Star,600+位 Contributors。 Github 地址:https://github.com/prometheus 。
- **开发语言 :**Go
- 数据存储 : Prometheus 自研一套高性能的时序数据库,并且还支持外接时序数据库。
- 数据采集方式 : Prometheus 的基本原理是通过 HTTP 协议周期性抓取被监控组件的状态,任意组件只要提供对应的 HTTP 接口就可以接入监控。Prometheus 在收集数据时,采用的 Pull 模型(服务端主动去客户端拉取数据)
- **数据展示 :**自带展示界面,也可以对接 Grafana。
- **评价 :**目前国内外使用最广泛的一个监控系统,生态也非常好,成熟稳定!
Prometheus 特性 :
- 开箱即用的各种服务发现机制,可以自动发现监控端点;
- 专为监控指标数据设计的高性能时序数据库 TSDB;
- 强大易用的查询语言PromQL以及丰富的聚合函数;
- 可以配置灵活的告警规则,支持告警收敛(分组、抑制、静默)、多级路由等等高级功能;
- 生态完善,有各种现成的开源 Exporter 实现,实现自定义的监控指标也非常简单。
Prometheus 基本架构 :
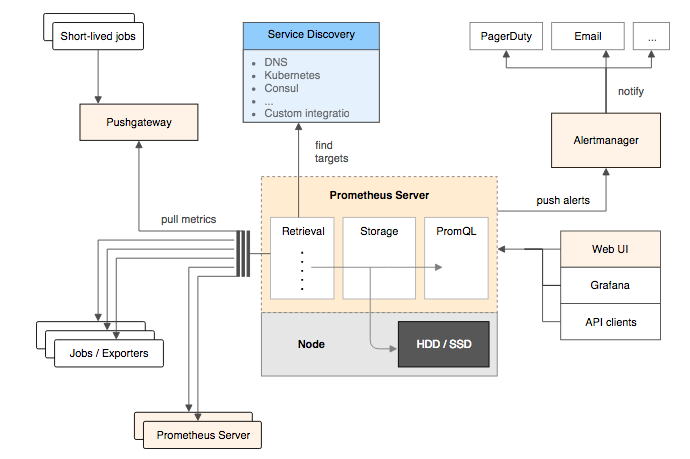
- Prometheus Server:核心组件,用于收集、存储监控数据。它同时支持静态配置和通过 Service Discovery 动态发现来管理监控目标,并从监控目标中获取数据。此外,Prometheus Server 也是一个时序数据库,它将监控数据保存在本地磁盘中,并对外提供自定义的 PromQL 语言实现对数据的查询和分析。
- Exporter:用来采集数据,作用类似于 agent,区别在于 Prometheus 是基于 Pull 方式拉取采集数据的,因此,Exporter 通过 HTTP 服务的形式将监控数据按照标准格式暴露给 Prometheus Server,社区中已经有大量现成的 Exporter 可以直接使用,用户也可以使用各种语言的 client library 自定义实现。
- Push gateway:主要用于瞬时任务的场景,防止 Prometheus Server 来 pull 数据之前此类 Short-lived jobs 就已经执行完毕了,因此 job 可以采用 push 的方式将监控数据主动汇报给 Push gateway 缓存起来进行中转。
- 当告警产生时,Prometheus Server 将告警信息推送给 Alert Manager,由它发送告警信息给接收方。
- Prometheus 内置了一个简单的 web 控制台,可以查询配置信息和指标等,而实际应用中我们通常会将 Prometheus 作为 Grafana 的数据源,创建仪表盘以及查看指标。
推荐一本 Prometheus 的开源书籍《Prometheus 操作指南》。
总结
- 监控是一项长期建设的事情,一开始就想做一个 All In One 的监控解决方案,我觉得没有必要。从成本角度考虑,在初期直接使用开源的监控方案即可,先解决有无问题。
- Zabbix、Open-Falcon 和 Prometheus 都支持和 Grafana 做快速集成,想要美观且强大的可视化体验,可以和 Grafana 进行组合。
- Open-Falcon 的核心优势在于数据分片功能,能支撑更多的机器和监控项;Prometheus 则是容器监控方面的标配,有 Google 和 k8s 加持。
日志系统常见面试题总结
因为日志系统在询问项目经历的时候经常会被问到,所以,我就写了这篇文章。
这是一篇日志系统常见概念的扫盲篇~不会涉及到具体架构的日志系统的搭建过程。旨在帮助对于日志系统不太了解的小伙伴,普及一些日志系统常见的概念。
何为日志?
在我看来,日志就是系统对某些行为的一些记录,这些行为包括:系统出现错误(定位问题、解决问题)、记录关键的业务信息(定位问题、解决问题)、记录操作行为(保障安全)等等。
按照较为官方的话来说:“日志是带时间戳的基于时间序列的机器数据,包括 IT 系统信息(服务器、网络设备、操作系统、应用软件)、物联网各种传感器信息。日志可以反映用户/机器的行为,是真实的数据”。
为何要用日志系统?
没有日志系统之前,我们的日志可能分布在多台服务器上。每次需要查看日志,我们都需要登录每台机器。然后,使用 grep、wc 等 Linux 命令来对日志进行搜索。这个过程是非常麻烦并且耗时的!并且,日志量不大的时候,这个速度还能忍受。当日志量比较多的时候,整个过程就是非常慢。
从上面我的描述中,你已经发现,没有对日志实现集中管理,主要给我们带来了下面这几点问题:
开发人员登录线上服务器查看日志比较麻烦并且存在安全隐患
日志数据比较分散,难以维护,不方便检索。
日志数量比较大的时候,查询速度比较慢。
无法对日志数据进行可视化展示。
日志系统就是为了对日志实现集中管理。它也是一个系统,不过主要是负责处理日志罢了。
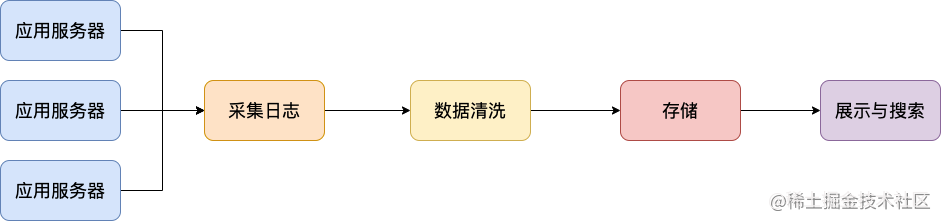
一个最基本的日志系统要做哪些事情?
为了解决没有日志系统的时候,存在的一些问题,一直最基本的 日志系统需要做哪些事情呢?
- **采集日志 :**支持多种日志格式以及数据源的采集。
- **日志数据清洗/处理 :**采集到的原始日志数据需要首先清洗/处理一波。
- **存储 :**为了方便对清洗后的日志进行处理,我们可以对接多种存储方式比如 ElasticSearch(日志检索) 、Hadoop(离线数据分析)。
- **展示与搜素 :**支持可视化地展示日志,并且能够根据关键词快速的定位到日志并查看日志上下文。
- **告警 :**支持对接常见的监控系统。
我专门画了一张图,展示一下日志系统处理日志的一个基本流程。
另外,一些比较高大上的日志系统甚至还支持 实时分析、离线分析 等功能。
ELK 了解么?
ELK 是目前使用的比较多的一个开源的日志系统解决方案,背靠是 Elastic 这家专注搜索的公司。
ELK 老三件套
最原始的时候,ELK 是由 3 个开源项目的首字母构成,分别是 Elasticsearch 、Logstash、Kibana。
下图是一个最简单的 ELK 日志系统架构 :
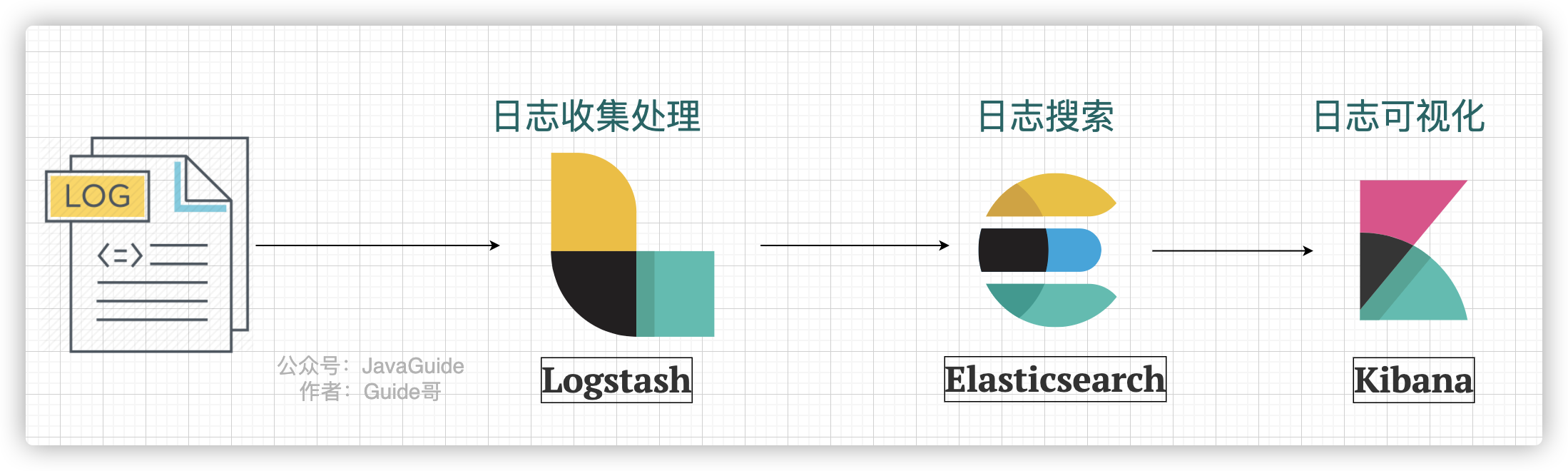
我们分别来介绍一下这些开源项目以及它们在这个日志系统中起到的作用:
- **Logstash :**Logstash 主要用于日志的搜集、分析和过滤,支持对多种日志类型进行处理。在 ELK 日志系统中,Logstash 负责日志的收集和清洗。
- **Elasticsearch :**ElasticSearch 一款使用 Java 语言开发的搜索引擎,基于 Lucence 。可以解决使用数据库进行模糊搜索时存在的性能问题,提供海量数据近实时的检索体验。在 ELK 日志系统中,Elasticsearch 负责日志的搜素。
- **Kibana :**Kibana 是专门设计用来与 Elasticsearch 协作的,可以自定义多种表格、柱状图、饼状图、折线图对存储在 Elasticsearch 中的数据进行深入挖掘分析与可视化。 ELK 日志系统中,Logstash 主要负责对从 Elasticsearch 中搜索出来的日志进行可视化展示。
新一代 ELK 架构
ELK 属于比较老牌的一款日志系统解决方案,这个方案存在一个问题就是:Logstash 对资源消耗过高。
于是, Elastic 推出了 Beats 。Beats 基于名为libbeat的 Go 框架,一共包含 8 位成员。

这个时候,ELK 已经不仅仅代表 Elasticsearch 、Logstash、Kibana 这 3 个开源项目了。
Elastic 官方将 ELK 重命名为 Elastic Stack(Elasticsearch、Kibana、Beats 和 Logstash)。但是,大家目前仍然习惯将其成为 ELK 。
Elastic 的官方文档是这样描述的(由 Chrome 插件 Mate Translate 提供翻译功能):
现在的 ELK 架构变成了这样:

Beats 采集的数据可以直接发送到 Elasticsearch 或者在 Logstash 进一步处理之后再发送到 Elasticsearch。
Beats 的诞生,也大大地扩展了老三件套版本的 ELK 的功能。Beats 组件除了能够通过 Filebeat 采集日志之外,还能通过 Metricbeat 采集服务器的各种指标,通过 Packetbeat 采集网络数据。
我们不需要将 Beats 都用上,一般对于一个基本的日志系统,只需要 Filebeat 就够了。
Filebeat 是一个轻量型日志采集器。无论您是从安全设备、云、容器、主机还是 OT 进行数据收集,Filebeat 都将为您提供一种轻量型方法,用于转发和汇总日志与文件,让简单的事情不再繁杂。
Filebeat 是 Elastic Stack 的一部分,能够与 Logstash、Elasticsearch 和 Kibana 无缝协作。
Filebeat 能够轻松地将数据传送到 Logstash(对日志进行处理)、Elasticsearch(日志检索)、甚至是 Kibana (日志展示)中。
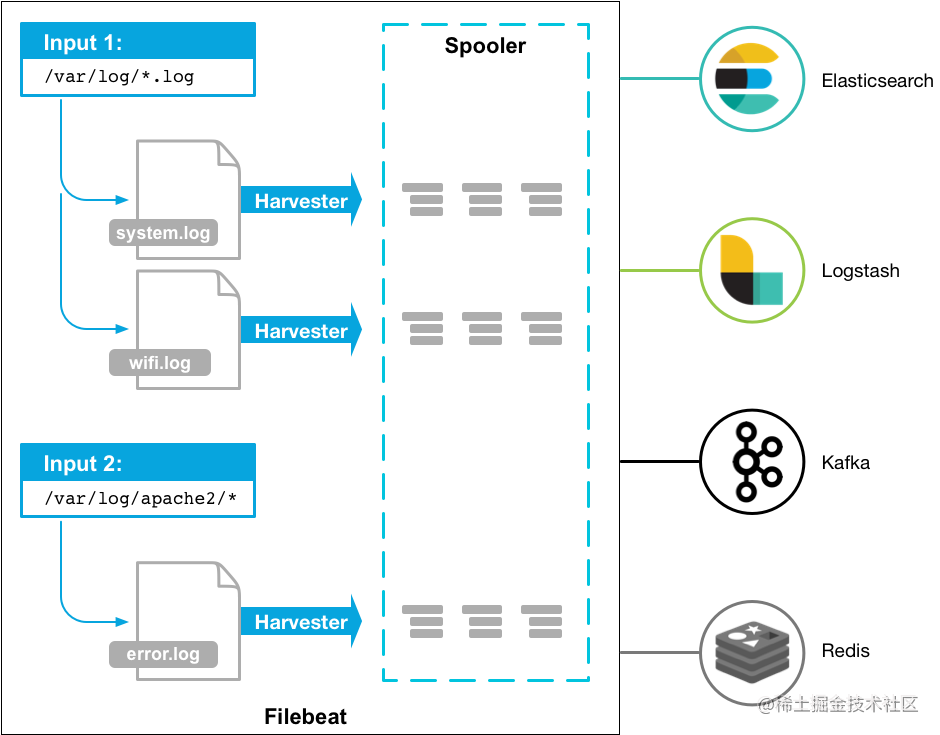
Filebeat 只是对日志进行采集,无法对日志进行处理。日志具体的处理往往还是要交给 Logstash 来做。
更多关于 Filebeat 的内容,你可以看看 Filebeat 官方文档教程。
Filebeat+Logstash+Elasticsearch+Kibana 架构概览
下图一个最基本的 Filebeat+Logstash+Elasticsearch+Kibana 架构图,图片来源于:《The ELK Stack ( Elasticsearch, Logstash, and Kibana ) Using Filebeat》。
Filebeat 替代 Logstash 采集日志,具体的日志处理还是由 Logstash 来做。
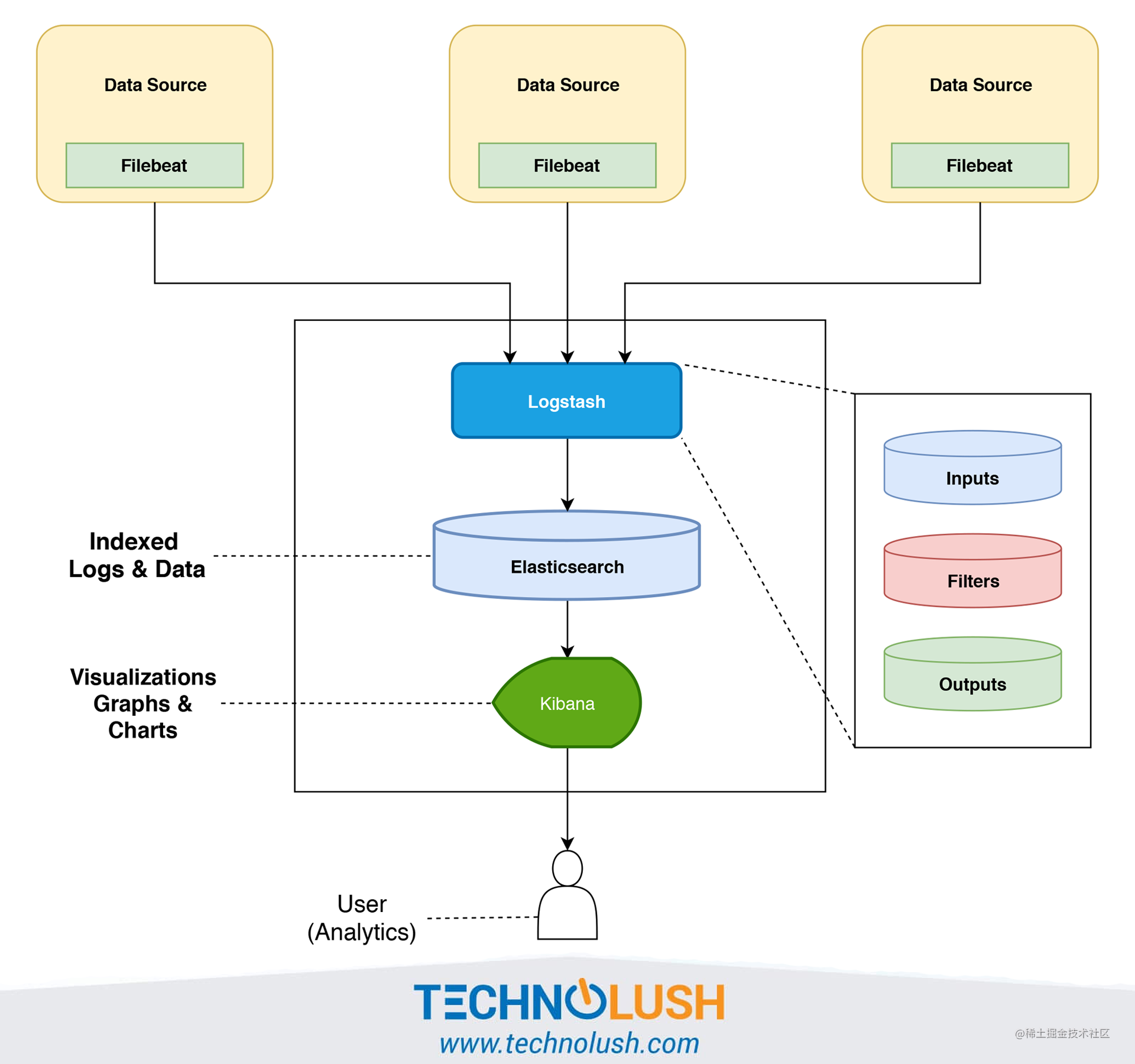
针对上图的日志系统架构图,有下面几个可优化点:
- 在 Kibana 和用户之间,使用 Nginx 来做反向代理,免用户直接访问 Kibana 服务器,提高安全性。
- Filebeat 和 Logstash 之间增加一层消息队列比如 Kafka、RabbitMQ。Filebeat 负责将收集到的数据写入消息队列,Logstash 取出数据做进一步处理。
EFK
EFK 中的 F 代表的是 Fluentd。下图是一个最简单的 EFK 日志系统架构 :
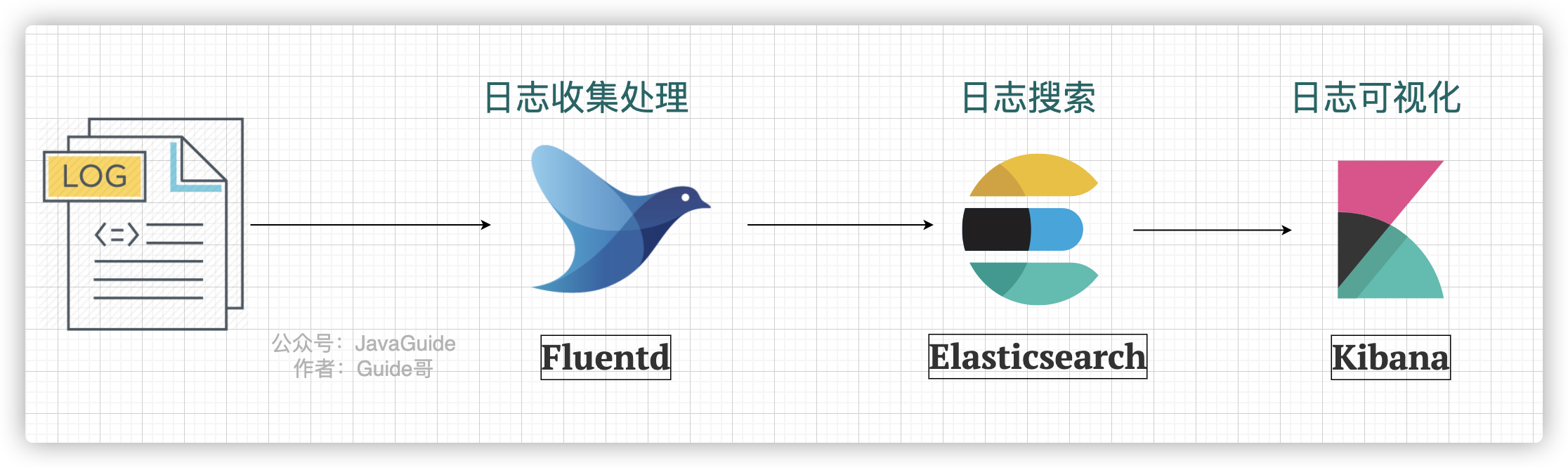
Fluentd 是一款开源的日志收集器,使用 Ruby 编写,其提供的功能和 Logstash 差不多。但是,要更加轻量,性能也更优越,内存占用也更低。具体使用教程,可以参考《性能优越的轻量级日志收集工具,微软、亚马逊都在用!》。
轻量级日志系统 Loki
上面介绍到的 ELK 日志系统方案功能丰富,稳定可靠。不过,对资源的消耗也更大,成本也更高。而且,用过 ELK 日志系统的小伙伴肯定会发现其实很多功能压根都用不上。
因此,就有了 Loki,这是一个 Grafana Labs 团队开源的小巧易用的日志系统,原生支持 Grafana。
并且,Loki 专门为 Prometheus 和 Kubernetes 用户做了相关优化比如 Loki 特别适合存储Kubernetes Pod 日志。
官方的介绍也比较有意思哈! Like Prometheus,But For Logs. (类似于 Prometheus 的日志系统,不过主要是为日志服务的)。

根据官网 ,Loki 的架构如下图所示
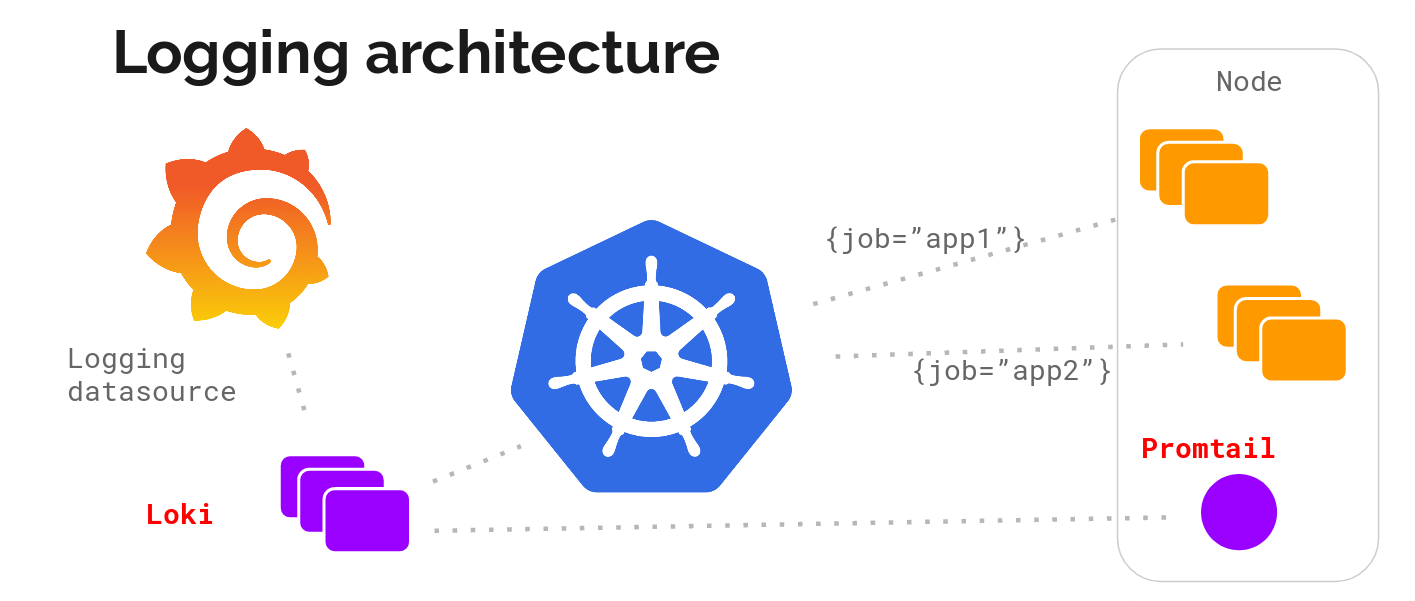
Loki 的整个架构非常简单,主要有 3 个组件组成:
- Loki 是主服务器,负责存储日志和处理查询。
- Promtail 是代理,负责收集日志并将其发送给 Loki 。
- Grafana 用于 UI 展示。
Loki 提供了详细的使用文档,上手相对来说比较容易。并且,目前其流行度还是可以的。你可以很方便在网络上搜索到有关 Loki 的博文。
总结
这篇文章我主要介绍了日志系统相关的知识,包括:
何为日志?
为何要用日志系统?一个基本的日志系统要做哪些事情?
ELK、EFK
轻量级日志系统 Loki
另外,大部分图片都是我使用 draw.io 来绘制的。一些技术名词的图标,我们可以直接通过 Google 图片搜索即可,方法: 技术名词+图标(示例:Logstash icon)
参考
ELK 架构和 Filebeat 工作原理详解:https://developer.ibm.com/zh/articles/os-cn-elk-filebeat/
ELK Introduction-elastic 官方 :https://elastic-stack.readthedocs.io/en/latest/introduction.html
ELK Stack Tutorial: Learn Elasticsearch, Logstash, and Kibana :https://www.guru99.com/elk-stack-tutorial.html